Text to Speech 분야를 공부하면서 딥러닝 모델을 학습시키기 전에 음성 데이터를 어떻게 input 형태로 변환하여 주는지 궁금했다. 이를 위해 음성 신호를 처리하는 기법들 중 기초적인 개념들에 대해 키워드 식으로 알아보자.
Sampling rate, SR(샘플링레이트)
- 이산적 신호를 얻기 위한 아날로그 신호의 단위 시간당 샘플링 횟수.
- 단위는 헤르츠 Hz (1/s, s^-1)
- 샘플링 레이트에 따라 푸리에 변환으로 계산되는 최대 주파수 정보가 정해진다
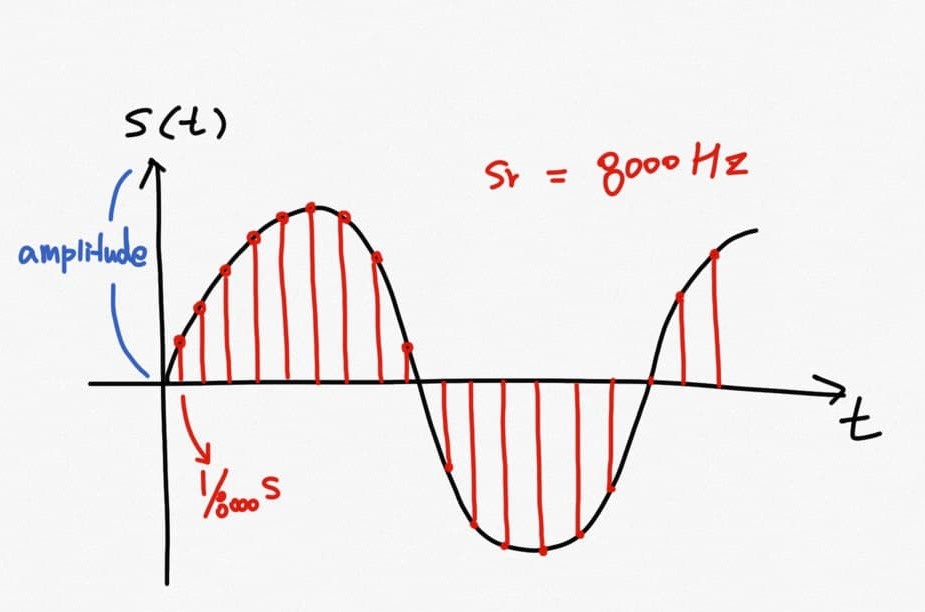
Discrete Fourier Transform, DFT(이산 푸리에 변환)
- 음성 신호를 0 ~ sampling rate Hz 범위에 해당하는 주파수 별 크기(magnitude) & 위상(phase) 값으로 변환
- 그냥 푸리에 변환(Fourier Transform, FT)은 아날로그 신호를 +-∞(무한대)의 시간으로 나누어 주파수를 계산하여 적분
∴ sampling 된 이산 신호의 경우 DFT를 이용해 주파수 성분을 계산한다.
이산 푸리에 변환을 할 때 속도가 느려 보통 Fast Fourier Transform, FFT를 사용한다. 이때, fft size라는 인자가 등장하게 된다. 모든 주파수 성분을 계산하는 것이 아니라 표본 개수를 정해 그만큼에 해당하는 영역만 계산하여 빠르고 효율적인 변환을 수행한다.
- n_fft(fft size): 연속적인 주파수를 이산적인 영역으로 나누는 것
[예를 들어보자] sr = 44100, n_fft = 32으로 FFT를 한다는 것은
주파수가 0, 44100/(32/1), 44100/(32/2),... 44100/(32/16)의 영역으로 나누어 각 주파수의 크기(magnitude)와 위상(phase)을 계산한다. 최대 sampling rate의 절반까지 n_fft 등분하여 각 주파수 영역에 대해 이산 푸리에 변환을 수행하는 것이다.
왜 sampling rate의 절반까지만 해당하는 주파수 영역 성분을 분석할 수 있는 거지? Nyquist 이론에 의하면 그렇다고 함. 이 부분은 더 공부가 필요합니다 :)

Short-Time Fourier Transform, STFT
- 음성 신호는 시간에 따라 크게 바뀌는 특성이 있다. 예를 들어, "안녕하세요"라는 말을 발음하는 1초 음성이 있다고 하면 작은 시간 동안 음성 신호의 특징이 무수히 많이 바뀐다는 것을 짐작할 수 있다.
- DFT/FFT는 이를 인지하지 못하고 음성 신호 전체 길이에 대하여 주파수 성분을 분석하기 때문에 음성 신호의 특성을 파악하기에 한계가 있다.
- 따라서 일정 시간 구간(window size)으로 나누고 각 구간에 대해 FFT를 수행하여 Spectrogram 형태로 주파수 성분을 분석하는 방법이 STFT이다.
[예를 들어보자] sr = 8000, n_fft = 32, window_size = 100으로 STFT를 한다는 것은
8000Hz sampling rate를 가지는 1초의 음성신호를 STFT 할 때, window size가 100이라면 12.5ms(1초에 8000번 샘플링 중 100개 샘플을 하나의 window로 가지니 100/8000초)의 구간씩 나누어서 STFT를 한다는 말. 그리고 0~8000Hz 구간을 17개(n_fft/2+1)의 bin으로 나누어 각 영역별 주파수 성분(magnitude, phase)을 계산한다는 말.
마치며
딥러닝 모델에 입력으로 음성 신호를 넣어주기 위해서는 주파수 영역으로의 변환이 필요하다.
이를 위해 Short-Time Fourier Transform, STFT를 수행하고 있으며 이 변환을 알기 위해 필요한 개념들을 정리해 보았다.
'Deep Learning > Speech Synthesis' 카테고리의 다른 글
| [정리] Neural Vocoder에 대해 알아보자 (3) | 2021.03.03 |
|---|---|
| 대표적인 TTS Datasets (LJ, KSS, VCTK) (0) | 2021.03.03 |
| [Intro] Speech Synthesis | Text to Speech (TTS) (2) | 2021.03.02 |