이전 글에서는 Text-to-Speech(TTS)의 연구 동향에 대해 알아보았다.
이번 글에서는 TTS에서 Vocoder 부분에 대해 좀 더 자세히 알아보고자 한다.
(HiFi-GAN [1] 논문의 introduction 내용을 주로 참고하였음)
Vocoder의 역할
Neural Speech Synthesis는 크게 2-stage pipeline으로 이루어져 있다.
- Text로부터 Mel-spectrogram이나 linguistic feature와 같은 low resolution intermediate representation을 예측
- Low resolution representation으로부터 raw waveform audio를 예측
여기서 Vocoder의 역할은 2번째 stage를 수행하는 것이다.

위 그림은 TTS 모델에 해당하는 Deep Voice3 [2]와 Tacotron2 [3]의 구조도이다. 입력 텍스트로부터 합성 음성을 만들어내는 과정이며 이 중 빨간색 박스로 지정한 부분이 Vocoder 영역에 해당한다.
Mel-spectrogram에서 audio를 예측하는 부분을 조금 더 설명하자면, 원래 audio를 mel-spectrogram으로 변환하는 과정은 다음과 같다.

audio를 주파수 영역에서 분석하기 위해 Short-time Fourier transform(STFT)를 수행하여 주파수 성분에 해당하는 특징점을 추출할 수 있다. 이 중에서 크기 성분에 해당하는 magnitude 값을 이용해 Mel-filterbank를 적용시키고 Mel-scale로 변환시켜주면 Mel-spectrogram을 얻어낼 수 있다. 사실, 주파수 성분의 크기(magnitude) 값과 위상(phase) 값을 알고 있다면 STFT 변환은 역변환이 가능하기 때문에 정보 손실 없이 원본 음성을 복원해 낼 수 있다. 하지만 보통 Mel-spectrogram을 예측하고 학습하는 TTS 모델의 경우에 주파수 성분의 크기 정보만 알아낼 수 있기 때문에 원본 음성을 예측하기 위해서는 위상 정보를 예측하고 이를 바탕으로 원본 음성을 예측해야 한다. 이 기능을 수행하는 것이 Vocoder이다.
Griffin-Lim
Neural Vocoder 이전에 전통적인 방법의 Vocoder 기술로 Griffin-Lim 알고리즘이 있다.
Griffin-Lim 알고리즘은 Mel-spectrogram으로 계산된 STFT magnitude 값만 가지고 원본 음성을 예측하는 rule-based 알고리즘이다. 원본 음성 신호를 복원하기 위해서는 STFT magnitude 값과 STFT phase 값이 필요하기 때문에 이 phase(위상) 값을 임의로 두고 예측을 시작한다. 그렇게 예측된 음성의 STFT magnitude 값과 원래 Mel-spectrogram으로 계산된 STFT magnitude 값의 mean squared error(MSE)가 최소가 되도록 반복 수행하여 원본 음성을 찾아낸다.
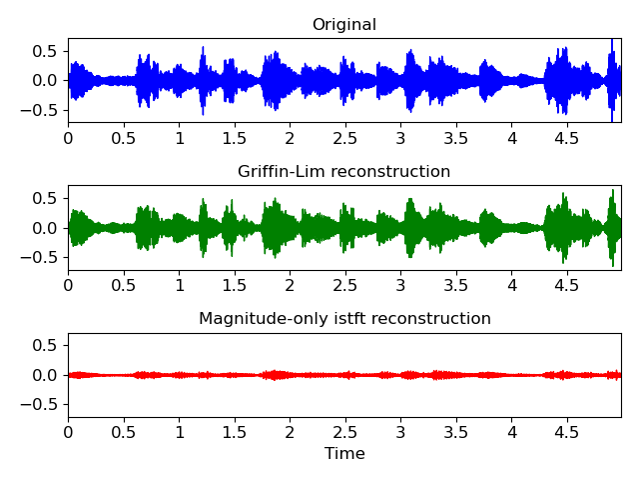
실제로 Griffin-Lim을 이용해 복원을 수행해보면 나름 원본 음성을 잘 복원해 내는 것을 확인할 수 있다. 하지만 정말 자연스러운 음성을 복원해주지는 못하기 때문에 서비스에 활용되기에는 어렵다고 판단된다. 따라서 Vocoder에 대한 연구가 활발하게 진행되는 것 같다.
Neural Vocoder
Auto-Regressive Generative model - WaveNet
Auto-Regressive Generative model인 PixelCNN을 음성 분야에 활용시킨 WaveNet[5]은 기존의 Concatenative, Parametric 모델이 학습한 음성보다 월등히 좋은 퀄리티의 음성을 합성하였다. 하지만 AR 모델의 특성상 학습과 추론에 너무 많은 시간이 소요된다는 단점이 존재하여 이를 보완하기 위한 연구가 진행되었다.
Flow-based Generative model
Parallel WaveNet[6], WaveGlow [7]와 같은 Flow-based 모델이 등장하면서 합성 음성의 퀄리티와 속도라는 두 마리 토끼를 잡아내었다. 하지만 WaveGlow 같은 경우 모델에 너무 많은 개수의 파라미터가 필요로 한다는 단점이 존재하였다.

위 그림처럼 Flow-based 모델인 WaveGlow 모델은 WaveNet보다 높은 MOS 점수를 받으며 합성 음성의 퀄리티가 좋다는 것을 확인할 수 있지만, MelGAN 논문에서 보이는 것처럼 WaveGlow 모델의 파라미터 개수는 WaveNet에 비해 4배 보다 조금 안될 정도로 많다는 것을 확인할 수 있다.
Generative Adversarial Network model (GAN)
위 두 모델의 단점을 개선하기 위해 합성 음성의 퀄리티는 다소 떨어질 수 있으나 속도와 파라미터 개수 부분에서 효율적으로 개선시킬 수 있는 GAN 모델에 대한 연구도 진행되어오고 있다. 대표적으로 MelGAN [8]이 있고 그 뒤로 GAN-TTS [9], HiFi-GAN [1], VocGAN [10] 등이 있다.

위 성능 표에서 확인할 수 있듯이 MelGAN과 GAN-TTS같이 GAN 모델의 경우 기존의 방법들에 비해 MOS 값이 상대적으로 낮다. 하지만 속도나 파라미터 개수 부분에서 효율적으로 개선이 되었고 또 최근에 카카오에서 발표한 HiFi-GAN 모델의 경우에는 합성 음성의 퀄리티 부분에서도 개선을 보이며 기존의 방법들보다 높은 MOS 값을 가지며 세 마리 토끼를 동시에 잡았다고 한다.
Timeline of Neural Vocoder
예전에 object detection 모델에 대한 공부를 하면서 hoya님의 정리 내용을 인상깊게 보고 배워서 나도 이번에 다른 사람들에게 도움이 되고자 Neural Vocoder 모델을 정리해 보았다. 학회의 순서까지 고려하지는 못했지만 전반적인 흐름을 익히는 데 참고하셨으면 좋겠다. 빨간색으로 표시한 모델들은 Neural Vocoder의 대표적인 모델로 공부하실 때 꼭 보면 좋을 것 같다.

Reference
[1] Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. "HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis." arXiv preprint arXiv:2010.05646 (2020).
[2] Ping, Wei, et al. "Deep voice 3: Scaling text-to-speech with convolutional sequence learning." arXiv preprint arXiv:1710.07654 (2017).
[3] Shen, Jonathan, et al. "Natural tts synthesis by conditioning wavenet on mel spectrogram predictions." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
[4] librosa.org/doc/main/generated/librosa.griffinlim.html
[5] Oord, Aaron van den, et al. "Wavenet: A generative model for raw audio." arXiv preprint arXiv:1609.03499 (2016).
[6] Oord, Aaron, et al. "Parallel wavenet: Fast high-fidelity speech synthesis." International conference on machine learning. PMLR, 2018.
[7] Prenger, Ryan, Rafael Valle, and Bryan Catanzaro. "Waveglow: A flow-based generative network for speech synthesis." ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019.
[8] Kumar, Kundan, et al. "Melgan: Generative adversarial networks for conditional waveform synthesis." arXiv preprint arXiv:1910.06711 (2019).
[9] Bińkowski, Mikołaj, et al. "High fidelity speech synthesis with adversarial networks." arXiv preprint arXiv:1909.11646 (2019).
[10] Yang, Jinhyeok, et al. "VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network." arXiv preprint arXiv:2007.15256 (2020).
'Deep Learning > Speech Synthesis' 카테고리의 다른 글
| [개념 정리] 음성 신호 처리 개념들 키워드 정리 (3) | 2021.03.16 |
|---|---|
| 대표적인 TTS Datasets (LJ, KSS, VCTK) (0) | 2021.03.03 |
| [Intro] Speech Synthesis | Text to Speech (TTS) (2) | 2021.03.02 |