ICCV 2019 논문 리뷰 중에 Visual Ground 이라는 키워드가 계속 보이길래 찾아보았다.
Visual Grounding
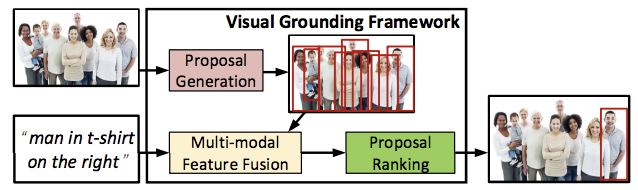
General task of locating the components of a structured description in an image
- Conser, Erik, et al. "Revisiting Visual Grounding." arXiv preprint arXiv:1904.02225 (2019)
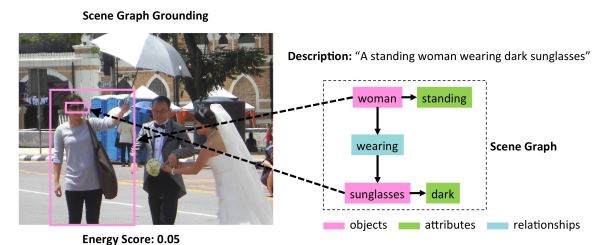
즉, 이미지에서 어느 부분을 묘사하였는지 bounding box로 표시하는 것을 의미하며 묘사는 정형화 된 표현으로 제공된다. 그리고 structured description은 대표적으로 'scene graph' 형태나 'subject-predicate-object' 형태의 정형화 된 자연어 구로 표현된다.
[Scene graph] - 'A standing woman wearing dark sunglasses'
[Subject-predicate-object] - 'A horse following a person'

Visual Grounding의 목적은 query를 입력 이미지의 적절한 위치에 표시(grounding)하는 것이다.
Visual Grounding과 유사한 주제로 'phrase localization'[3], 'referring expression comprehension'[4], 'natural language object retrieval'[5], 'visual question segmentation'[6] 등과 같은 이름의 연구들이 존재한다.
Visual Grounding을 잘 활용한다면 'Question Answering', 'Image Captioning', 'Image retrieval' 분야에 적용이 가능하다.
Reference
[1] Yu, Zhou, et al. "Rethinking diversified and discriminative proposal generation for visual grounding." arXiv preprint arXiv:1805.03508 (2018).
[2] Conser, Erik, et al. "Revisiting Visual Grounding." arXiv preprint arXiv:1904.02225 (2019)
[3] Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. International journal of computer vision, 123(1):74–93, 2017.
[4] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
[5] Ronghang Hu, Huazhe Xu, Marcus Rohrbach, Jiashi Feng, Kate Saenko, and Trevor Darrell. Natural language object retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4555–4564, 2016.
[6] Chuang Gan, Yandong Li, Haoxiang Li, Chen Sun, and Boqing Gong. Vqs: Linking segmentations to questions and answers for supervised attention in vqa and question-focused semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1811–1820, 2017.
'Deep Learning > Object Detection' 카테고리의 다른 글
| [용어 정리] class-agnostic 이란 (1) | 2019.11.07 |
|---|---|
| [용어 정리] Salient Object Detection(SOD) 이란 - 중요 물체 검출 (1) | 2019.11.07 |
| [Intro] Object Detection using Deep Learning (2) | 2019.09.16 |